

6��19��-20�գ�����Ӌ���I���ИI���ʢ�¡������R�d�ƿƼ��Ї������AWS Summit�� ���Ϻ���������ʢ���e�С����鱾�÷���y��ٝ���̣�Zenlayer �y���� AI ���A�Oʩ��Q�������࣬ͨ�^����չ�_ȫ��λչʾ���®aƷ�ɹ���
��6��20�ա���������_�������h���У�Zenlayer ����Q�����ܘ�������㑰l�����}���v��AI ȫ���{���c Token ��ݔ���������������������I AI ����ʹ�c�c�ƾ�֮����
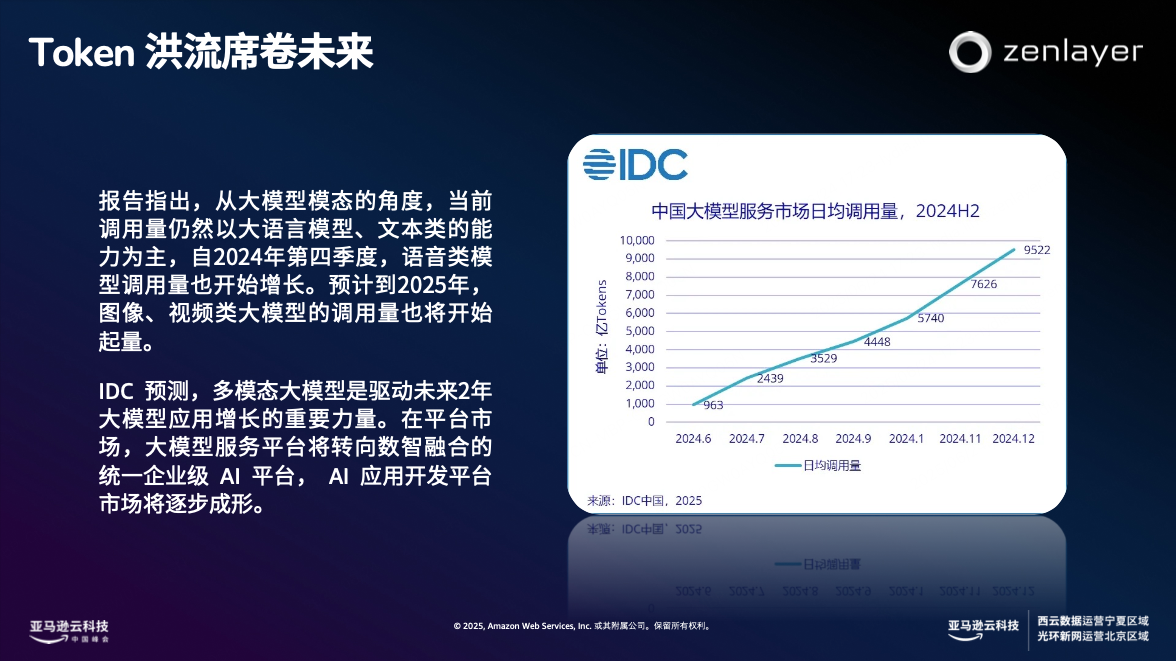
AI ģ���{�Õr�����������𣺅fͬ�y�����t�ߡ��_�N��
��ǰ��ģ�͵ĺ��İlչڅ�ݴ��������P�I����ģ�B�ںϡ���ģ�ͅfͬ�Լ� RAG �ܘ��ռ���
IDC �A�y����ģ�B��ģ������δ�� 2 ���ģ�͑������L����Ҫ��������ƽ�_�Ј�����ģ�ͷ���ƽ�_���D�����ںϵĽyһ��I�� AI ƽ�_����ģ�ͅfͬ��u�ɞ� AI �������������������˽��� AI ���X����������ݔ���Ĝʴ_�ȣ�RAG �ܘ���u�ɞ� AI ����Ę��䡣
���@һڅ���£�AI �������mȻ�õ��������s�ԏ��s�ȡ��ɱ��c���t����r����I���� AI �r�������أ�
1. ģ�ͽ����c��������
• ��ģ�ͽ�����s����ͬģ�͵� API �ӿڡ�������ʽ���{�÷�ʽ�������_�l�ͼ��ɵĹ������ɱ���
• Token �ɱ������������㣬һ��������Iÿ���{�ô�ģ�͵� Token �������_ǧ�f�����HToken �{�������Ϳ��ܸ��_���f��Ԫ��
• �羳���t�c���D��������ݔ���t���أ�������Ї��{�������� OpenAI ģ�ͣ�ƽ�����t���_ 200ms ���ϣ��W�j���������Mһ�����l�I���Д��L�U��
• ϵ�y�����c��ɢӋ�M�����Q������ȫ���������ȼ����y�}�����茦�Ӷ���������Ӌ�Mϵ�y������ؓ�����ء�
2. RAG �����įB������
• �·���L�����t���ӣ�RAG �ܘ��Ķ���ͨ���@�����L푑��r�g
• Token ���ı�������Ҫƴ�Ӵ��������ģ�Token ����ͨ������ͨ��Ԓ�� 3-5 ����������
�����ָ������I��횾߂䡰�ͽ�̎�� + ���|����ݔ + ��ģ�ͅfͬ���������������ƽ������y�}��
Zenlayer AI Gateway�� AI ģ���{�ø��z��
ᘌ��ИIʹ�c��Zenlayer ������ Zenlayer AI Gateway ��Q������ͨ�^����ȫ���B�ӾW�j�c Zenlayer AI Gateway ƽ�_������I����˵��˵� AI ��������������ԓ����������ij�^���罻ƽ�_���F�_�l�\�S�ɱ����� 20%��

Zenlayer AI Gateway �� Zenlayer �Ƴ�����һ�� AI ����ƽ�_����ͨ�^�yһ�ӿڴ�������� AI ģ���{��Ч�ʡ�ԓ�aƷ�߂��Ĵ���Ĺ��ܣ�
1. �yһ���룬�o�p�ГQ
����ȫ������ AI ģ�ͣ���OpenAI��Claude��Amazon Bedrock�����aģ�͡��_Դģ�͵ȣ���ͨ�^�˜ʻ��ӿڽyһ����
֧��ģ��һ�I�ГQ������{�ã�����/�Ă䣩��������Ͷ�ģ�ͽ�����_�l���\�S���s�ȡ�
2. Token ��ݔ����
���؏�Ո���M���Z�x���棬�p���؏� Token ���ģ������m���� RAG����ģ�ͻ���{�õȸ� Token ������
3. ȫ��W�j����
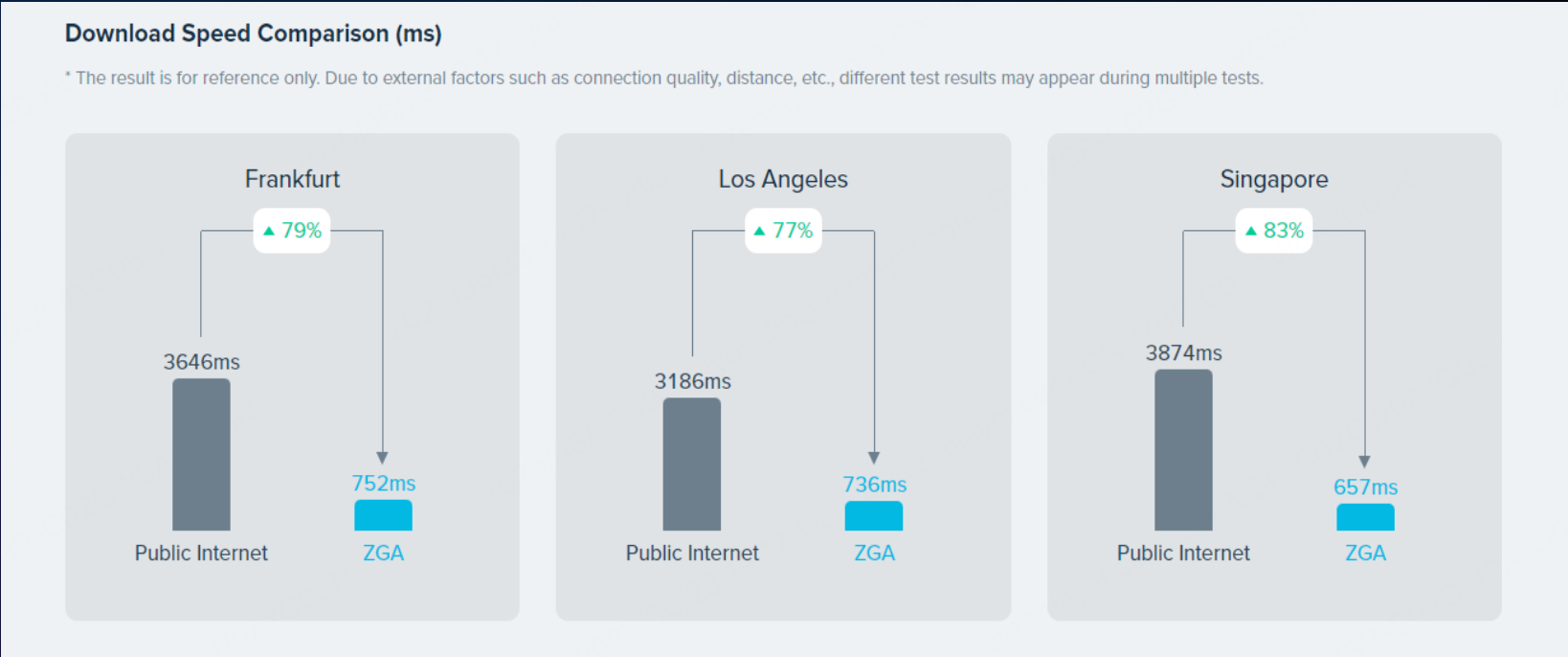
�ڶ��^������У��編�m�˸�����ɼ�����¼��£���1M Token Ո���W��ݔƽ���ĕr�s 3600 ms����ͨ�^ ZGA ߅�����ٿɃ������s 700ms ���ң����F 80% �������������@������ȫ���ȵ� AI 푑��ٶ��c�����ԡ�
4. ��I����ȫ�c�����`����
֧��˽�л����𣬼�����I�J�C�������Ƽ������^�V�����ϔ�����ȫ��
�ɼ����{�� Amazon �Ʒ��գ�Lambda/SageMaker/Bedrock������������� AI �����w
չ��δ�����挦��ģ�ͅfͬ�c RAG �ռ��Ĵ�څ�ݣ�Zenlayer ����������V����ȫ��W�j���ݣ�������� Zenlayer AI Gateway �aƷ������I�ṩ���`���Ч�������� AI ģ��ȫ���{���c Token ������Q������








